
The 3 AM pager alert. Slack channels exploding. A single, dreaded message cascades through the organization: “We’re seeing issues with us-east-1.” It’s the outage that every seasoned engineer knows is not a matter of if, but when. I’ve walked into companies where their entire multi-million dollar operation was pinned to a single AWS availability zone, let alone a single region. It’s a ticking time bomb, a single point of failure that keeps VPs awake at night.
Relying on one region is no longer a viable strategy for any serious production system. The business demands resilience. Your customers expect uptime. And you, the engineer, need a proven, automated way to survive a regional apocalypse. This is my blueprint for building a robust, multi-region failover architecture on AWS using Terraform. It’s not a theoretical exercise; it’s a battle-tested pattern for keeping the lights on when a whole slice of the internet goes dark.
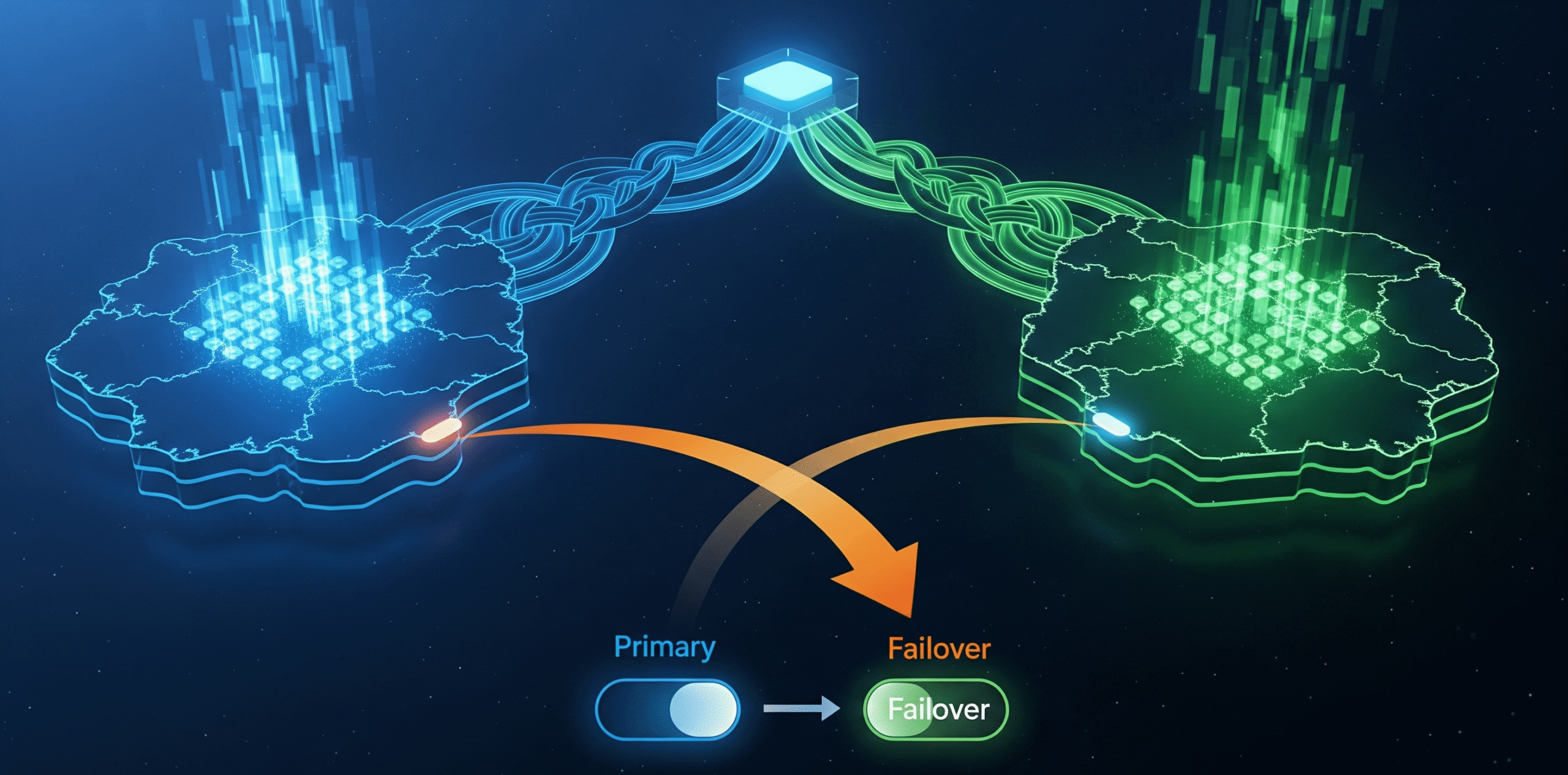
Architecture Context: The Active-Passive Blueprint
Before we touch a line of code, let’s get the strategy straight. We’re not building a hyper-complex, wallet-incinerating active-active system. For the vast majority of production-grade systems, a cost-effective and highly resilient active-passive setup is the optimal pattern.
Here’s the game plan:
- Primary Region (
us-east-1): Services all production traffic under normal conditions. - Failover Region (
us-west-2): A warm standby, continuously updated with data from the primary, ready to take over at a moment’s notice. - The Brains (Global Services): AWS Route 53 acts as the global traffic cop. It continuously runs health checks against our primary region. If it detects a failure, it automatically reroutes all user traffic to the failover region.
The core components for this architecture are:
- DNS: AWS Route 53 for health checks and DNS failover.
- Data (Database): Amazon Aurora Global Database for low-latency, cross-region database replication.
- Data (Object Storage): S3 Cross-Region Replication (CRR) for user uploads, assets, etc.
- Infrastructure: Everything defined as code in Terraform for repeatable, consistent deployments in both regions.
Here is what that looks like at a high level:

This design ensures that our state—the lifeblood of our application—is constantly replicated. When disaster strikes, the failover region isn’t starting from a cold, empty state; it’s ready to pick up right where the primary left off.
Implementation Details: The Terraform Code
Theory is one thing; implementation is another. Here’s how we build it. A common mistake I see is trying to cram multi-region logic into a single, monolithic Terraform state. This is a path to madness. The clean, maintainable approach is to isolate your regional infrastructure and manage your global services separately.
Our directory structure should look something like this:
├── modules/
│ ├── app-server/
│ └── database/
├── global/
│ ├── main.tf
│ └── outputs.tf
└── regions/
├── us-east-1/
│ └── main.tf
└── us-west-2/
└── main.tf
regions/: Defines two near-identical stacks for our primary and failover infrastructure.global/: Defines the Route 53 records and health checks that control the failover.
1. The DNS Failover Switch with Route 53
This is the heart of the mechanism. We’ll create a health check that monitors an endpoint in our primary region (e.g., a /health endpoint on our load balancer). Then, we create two A records for app.yourdomain.com: a primary one pointing to us-east-1 and a secondary one pointing to us-west-2.
Here’s the Terraform code for the global/main.tf file:
<span class="line"><span style="color: #6A737D"># Fetch outputs from our regional deployments</span></span>
<span class="line"><span style="color: #6F42C1">data</span><span style="color: #24292E"> </span><span style="color: #005CC5">"terraform_remote_state"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"primary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> backend</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"s3"</span></span>
<span class="line"><span style="color: #24292E"> config</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">{</span></span>
<span class="line"><span style="color: #24292E"> bucket </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"your-terraform-state-bucket"</span></span>
<span class="line"><span style="color: #24292E"> key </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"regions/us-east-1/terraform.tfstate"</span></span>
<span class="line"><span style="color: #24292E"> region </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"us-east-1"</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">data</span><span style="color: #24292E"> </span><span style="color: #005CC5">"terraform_remote_state"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"secondary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> backend</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"s3"</span></span>
<span class="line"><span style="color: #24292E"> config</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">{</span></span>
<span class="line"><span style="color: #24292E"> bucket </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"your-terraform-state-bucket"</span></span>
<span class="line"><span style="color: #24292E"> key </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"regions/us-west-2/terraform.tfstate"</span></span>
<span class="line"><span style="color: #24292E"> region </span><span style="color: #D73A49">=</span><span style="color: #24292E"> </span><span style="color: #032F62">"us-east-1"</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6A737D"># Health check to monitor the primary region's ALB</span></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_route53_health_check"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"primary_app_health"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> fqdn</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">terraform_remote_state</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary</span><span style="color: #D73A49">.</span><span style="color: #24292E">outputs</span><span style="color: #D73A49">.</span><span style="color: #24292E">alb_dns_name</span></span>
<span class="line"><span style="color: #24292E"> port</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #005CC5">443</span></span>
<span class="line"><span style="color: #24292E"> type</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"HTTPS"</span></span>
<span class="line"><span style="color: #24292E"> resource_path</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"/health"</span></span>
<span class="line"><span style="color: #24292E"> failure_threshold</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #005CC5">3</span></span>
<span class="line"><span style="color: #24292E"> request_interval</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #005CC5">30</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6A737D"># The public DNS record for our application</span></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_route53_record"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"app_primary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> zone_id</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"YOUR_HOSTED_ZONE_ID"</span></span>
<span class="line"><span style="color: #24292E"> name</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app.yourdomain.com"</span></span>
<span class="line"><span style="color: #24292E"> type</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"A"</span></span>
<span class="line"></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6F42C1">failover_routing_policy</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> type</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"PRIMARY"</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"></span>
<span class="line"><span style="color: #24292E"> set_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-primary-us-east-1"</span></span>
<span class="line"><span style="color: #24292E"> health_check_id</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws_route53_health_check</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary_app_health</span><span style="color: #D73A49">.</span><span style="color: #24292E">id</span></span>
<span class="line"><span style="color: #24292E"> </span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6F42C1">alias</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> name</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">terraform_remote_state</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary</span><span style="color: #D73A49">.</span><span style="color: #24292E">outputs</span><span style="color: #D73A49">.</span><span style="color: #24292E">alb_dns_name</span></span>
<span class="line"><span style="color: #24292E"> zone_id</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">terraform_remote_state</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary</span><span style="color: #D73A49">.</span><span style="color: #24292E">outputs</span><span style="color: #D73A49">.</span><span style="color: #24292E">alb_zone_id</span></span>
<span class="line"><span style="color: #24292E"> evaluate_target_health</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #005CC5">false</span><span style="color: #24292E"> </span><span style="color: #6A737D"># The health check does the work</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_route53_record"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"app_secondary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> zone_id</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"YOUR_HOSTED_ZONE_ID"</span></span>
<span class="line"><span style="color: #24292E"> name</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app.yourdomain.com"</span></span>
<span class="line"><span style="color: #24292E"> type</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"A"</span></span>
<span class="line"></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6F42C1">failover_routing_policy</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> type</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"SECONDARY"</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"></span>
<span class="line"><span style="color: #24292E"> set_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-secondary-us-west-2"</span></span>
<span class="line"><span style="color: #24292E"> </span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6F42C1">alias</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> name</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">terraform_remote_state</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary</span><span style="color: #D73A49">.</span><span style="color: #24292E">outputs</span><span style="color: #D73A49">.</span><span style="color: #24292E">alb_dns_name</span></span>
<span class="line"><span style="color: #24292E"> zone_id</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">terraform_remote_state</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary</span><span style="color: #D73A49">.</span><span style="color: #24292E">outputs</span><span style="color: #D73A49">.</span><span style="color: #24292E">alb_zone_id</span></span>
<span class="line"><span style="color: #24292E"> evaluate_target_health</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #005CC5">false</span></span>
<span class="line"><span style="color: #24292E"> }</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>This is elegant and powerful. If the health check fails three consecutive times, Route 53 automatically stops sending traffic to the primary record and activates the secondary. The failover is automatic.
2. Replicating the Database with Aurora Global Database
Your database is your center of gravity. For true disaster recovery, you need zero-data-loss failover. Aurora Global Database is built for this. It uses dedicated infrastructure to replicate data across regions with typical latency under one second.
In your primary region’s Terraform (regions/us-east-1/main.tf):
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_global_cluster"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"main"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> global_cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-global-database"</span></span>
<span class="line"><span style="color: #24292E"> engine</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"aurora-postgresql"</span></span>
<span class="line"><span style="color: #24292E"> engine_version</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"13.7"</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_cluster"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"primary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> provider</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary </span><span style="color: #6A737D"># Assuming provider alias for us-east-1</span></span>
<span class="line"><span style="color: #24292E"> global_cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws_rds_global_cluster</span><span style="color: #D73A49">.</span><span style="color: #24292E">main</span><span style="color: #D73A49">.</span><span style="color: #24292E">id</span></span>
<span class="line"><span style="color: #24292E"> cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-primary-cluster"</span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6A737D"># ... other params like engine, master_username, etc.</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_cluster_instance"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"primary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> provider</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary</span></span>
<span class="line"><span style="color: #24292E"> cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws_rds_cluster</span><span style="color: #D73A49">.</span><span style="color: #24292E">primary</span><span style="color: #D73A49">.</span><span style="color: #24292E">id</span></span>
<span class="line"><span style="color: #24292E"> instance_class</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"db.r6g.large"</span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6A737D"># ... etc.</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>In your failover region’s Terraform (regions/us-west-2/main.tf):
<span class="line"><span style="color: #6F42C1">data</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_global_cluster"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"main"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> provider</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary </span><span style="color: #6A737D"># Assuming provider alias for us-west-2</span></span>
<span class="line"><span style="color: #24292E"> global_cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-global-database"</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_cluster"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"secondary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> provider</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary</span></span>
<span class="line"><span style="color: #24292E"> global_cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">data</span><span style="color: #D73A49">.</span><span style="color: #24292E">aws_rds_global_cluster</span><span style="color: #D73A49">.</span><span style="color: #24292E">main</span><span style="color: #D73A49">.</span><span style="color: #24292E">id</span></span>
<span class="line"><span style="color: #24292E"> cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"app-secondary-cluster"</span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6A737D"># Note: no master username/password, it's inherited</span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6A737D"># ... etc.</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>
<span class="line"><span style="color: #6F42C1">resource</span><span style="color: #24292E"> </span><span style="color: #005CC5">"aws_rds_cluster_instance"</span><span style="color: #24292E"> </span><span style="color: #005CC5">"secondary"</span><span style="color: #24292E"> {</span></span>
<span class="line"><span style="color: #24292E"> provider</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary</span></span>
<span class="line"><span style="color: #24292E"> cluster_identifier</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #24292E">aws_rds_cluster</span><span style="color: #D73A49">.</span><span style="color: #24292E">secondary</span><span style="color: #D73A49">.</span><span style="color: #24292E">id</span></span>
<span class="line"><span style="color: #24292E"> instance_class</span><span style="color: #E36209"> </span><span style="color: #D73A49">=</span><span style="color: #E36209"> </span><span style="color: #032F62">"db.r6g.large"</span></span>
<span class="line"><span style="color: #24292E"> </span><span style="color: #6A737D"># ... etc.</span></span>
<span class="line"><span style="color: #24292E">}</span></span>
<span class="line"></span>The key is the global_cluster_identifier. By sharing it, we tell AWS to link these two clusters. The secondary becomes a readable replica of the primary. Promoting the secondary to primary during a real failover is a separate, well-documented process you must script and test.
Architect’s Note
Your failover plan is a fantasy until you’ve tested it. I mean really tested it. Automate your failover drills. Use a tool like the AWS Fault Injection Simulator (FIS) to simulate a regional outage in a non-production environment. Run a quarterly “Game Day” where you execute the full failover and failback procedure. The goal isn’t to see if it works; it’s to find out what breaks when it does. The business won’t thank you for a theoretical plan; they’ll thank you for one that survives contact with reality.
Pitfalls & Optimisations
Building this is one thing; running it in production is another. Here’s where the real-world experience comes in.
- Pitfall: The Split-Brain Problem. During a failover, you must ensure the old primary is completely fenced off. If it comes back online and starts accepting writes while your new primary is also active, you have a split-brain scenario—a nightmare to reconcile. Your failover script must include steps to isolate the old primary (e.g., by changing security group rules to block all traffic).
- Pitfall: Secret and Configuration Drift. How do you manage secrets (
DATABASE_URL, API keys) across regions? A parameter in SSM inus-east-1isn’t available inus-west-2. You need a multi-region replication strategy for your configuration and secrets. AWS Secrets Manager allows you to replicate secrets across regions. For configuration, ensure your CI/CD pipeline deploys changes to both regions simultaneously. - Optimisation: Cost Management with a “Pilot Light” Approach. A full hot standby can double your AWS bill. Consider a “pilot light” model for your failover region. Instead of running a full fleet of application servers, run just a minimal number (e.g., one or two). In a failover event, your runbook will include a step to scale up the Auto Scaling Group to full capacity. This drastically reduces cost while keeping your recovery time objective (RTO) low. Your database and S3 data are still fully replicated; you’re just saving on compute until you need it.
“Unlocked”: Your Key Takeaways
- Embrace Active-Passive: For most applications, a cost-effective active-passive architecture provides robust disaster recovery without the complexity of an active-active setup.
- Automate DNS Failover: Use AWS Route 53 with Health Checks as the automatic switch. This is the single most important component for a low RTO.
- Isolate Regional Infrastructure: Structure your Terraform code to manage each region independently, with a separate
globalconfiguration for services like Route 53. This prevents a blast radius from a faultyterraform apply. - Replicate Your State: Your data is everything. Use services designed for cross-region replication like Aurora Global Database and S3 CRR to ensure your failover region is always ready.
- Test, Test, and Test Again: A failover plan that hasn’t been tested is not a plan; it’s a hope. Run regular, automated drills to prove your system works as designed.
Surviving a regional outage isn’t about luck; it’s about deliberate, sober engineering. By codifying your infrastructure and automating your failover mechanisms, you turn a potential catastrophe into a manageable, non-eventful incident.
If your team is facing this challenge, I specialize in architecting these secure, audit-ready systems.
Email me for a strategic consultation: [email protected]
Explore my projects and connect on Upwork: https://www.upwork.com/freelancers/~0118e01df30d0a918e

